CPU Optimisation
06 Nov 2019 by Simon Greaves
CPU Scheduler
The CPU Scheduler, as the name suggests, schedules the CPU. It schedules the virtual CPUs on the VM (vCPUs) on the physical CPUs on the host (pCPUs). The CPU Scheduler enforces a proportional-share algorithm for CPU usage across all virtual machines and VMkernel processes on the ESXi host. It enables support for symmetric multiprocessing (SMP) VMs. It also allows for the use of relaxed co-scheduling for SMP VMs. Read on for more information on these topics!
Worlds
It all begins with worlds. A world is an ‘execution context’ that is scheduled on a processor, basically it’s like a process that runs on conventional Operating Systems. On conventional Operating Systems, such as Microsoft Windows installed on physical hardware, like your laptop, the ‘execution context’ corresponds to a process or a thread, on ESXi it corresponds to a world.
The CPU Schedulers role here is to assign execution context (processes/threads) to the actual processors requesting it in a way that ensures the actual processor can remain responsive to requests, to meet the system throughput requirements and hit utilization targets.
Types of Virtual Worlds
A VM is made up of a group of worlds, made up of the following types:
- One world for each vCPU assigned to a VM –One for mouse, keyboard, screen (MKS). A process responsible for rendering guest video and guest OS user input.
- One for the Virtual Machine Monitor (VMM). A process that runs in the VMkernel responsible for virtualising the guest OS instructions and managing virtual machine memory, storage and network I/O requests. One VMM per vCPU.
Types of Non-Virtual Worlds (VMkernel world)
- Idle World
- Driver World
- vMotion World
- West World (Ok I made that last one up!)
The CPU Scheduler decides which processor to schedule the world on. The CPU Scheduler allocates the CPU resources and coordinates CPU usage.
CPU Resource Allocation
One of the main tasks that the CPU scheduler performs is to choose which world is to be scheduled to a processor. If a CPU is already occupied that the scheduler wants to use, the schedule decides whether to preempt the current running world and to swap it for the one waiting to be scheduled.
The scheduler can migrate a world from a busy processor to an idle processor. This migration occurs if the physical CPU has become idle and is ready to receive more worlds or if the another world is ready to be scheduled.
The schedulers job is to:
- Schedule vCPUs on physical CPUs
- Check the utilization of the CPU every 2-40ms and migrate vCPUs as required
CPU Usage Coordination
The CPU scheduler enforces fairness across all CPUs with a proportional-share algorithm. This will:
- Time-slice pCPUs across all VMs when CPU resources are overcommitted
- Prioritize each vCPU using resource allocation settings that have been defined, like shares, reservations and limits
As ESXi hosts implements the proportional-share based algorithm, when the CPU resources are overcommitted the ESXi host will time-slice the physical CPUs across all VMs so that each VM runs as if it had been allocated its configured number of virtual processors. The ESXi hosts role is to associate each world with a share of the total CPU resources on the host.
This association of resources is known as an entitlement. Entitlements are calculated from user-provided resource specifications like shares, reservations and limits. When making the scheduling decisions, the ratio of the consumed CPU resources to the entitlement is used as the priority of the world. If the world has consumed less than its entitlement, the world is considered high priority and will most likely be chosen by the scheduler to run next.
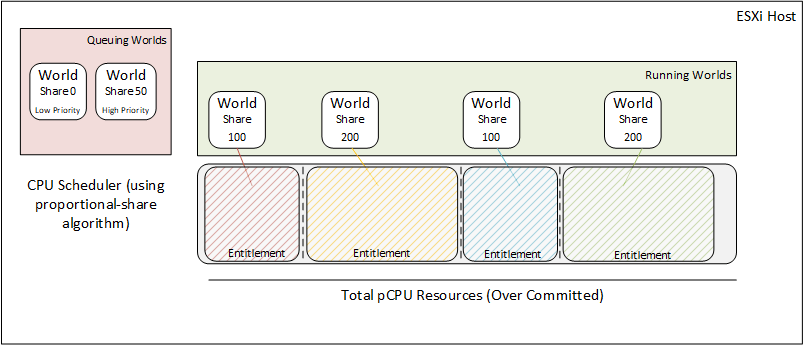
Co-Scheduling
Co-scheduling comes into effect when VMs have multiple CPUs allocated and require Symmetric Multi-Processing or SMP. Co-scheduling refers to a technique to scheduling these related processes to run on different processors at the same time.
At any time a vCPU might be scheduled, unscheduled, preempted or blocked whilst waiting for some event.
An ESXi hosts supports SMP VMs by enabling the SMP VM to present that they are running on a dedicated physical multiprocessor to the guest OS and applications.
Without this support for SMP VMs the vCPUs would be scheduled independently, which would break the guests assumptions regarding uniformed progress across all SMP vCPUs. This can lead to a situation where the vCPUs are skewed. Skewing means that one of the SMP vCPUs or more is running at a different speed to the others as its been scheduled whilst the others have queued. If the difference in the execution rates between the sibling vCPUs exceed a threshold the vCPU is considered skewed.
The progress is tracked between the vCPUs in the SMP vCPU by the CPU scheduler. A CPU is considered to be making progress if it is consuming the CPU in the guest level or if the CPU halts as it has finished its task.
Note: the time spent in the hypervisor is excluded from this progress track. This means that hypervisor execution might not be co-scheduled, that’s because not all operations in the hypervisor benefit from being co-scheduled. However when co-scheduling is beneficial, the hypervisor makes explicit co-scheduling requests to achieve good performance.
Relaxed co-scheduling
The purpose of relaxed co-scheduling is to schedule a subset of the VMs vCPUs simultaneously after skew has been detected. What Relaxed co-scheduling does is to lower the number of required physical CPUs for the virtual machine to co-start and increases CPU utilization. With relaxed co-scheduling, only the vCPUs that are skewed must be co-started, Relaxed co-scheduling ensures that when any vCPU is scheduled, all other vCPUs that are behind are also scheduled to reduce the skew.
Any vCPUs that have advanced too much are individually stopped to reduce the gap and allow the lagging vCPUs to catch up, then the stopped vCPUs can be started individually. Co-scheduling of all vCPUs is still attempted to maximize the performance benefit within the guest OS.
Note: An idle CPU has no co-scheduling overhead because the idle vCPU does not accumulate skew, as such it is treated as if it was running for co-scheduling purposes.
Processor Topology/Cache Awareness
The CPU Scheduler understands the physical processor layout, it’s number of sockets, cores and logical processors, It’s aware of the cache location of these processors which improves caching behavior such as maximizing cache utilization and improving cache affinity.
Cores in the same processor socket usually have a shared cache, also known as the last-level cache which acts as a memory cache between the cores on the socket and bypassing the memory bus. This leads to massive improvements in performance as the CPU last-level cache is significantly faster than the “still pretty fast” memory bus.
The scheduler spreads the load across all sockets to maximize the aggregate amount of cache available to improve performance. This is useful for SMP VMs to spread their load across the same socket and maximise the use of the cache.
Note: If you want to ensure that the SMP VMs will always use this behaviour you can set this setting in the VMX configuration file.
sched.cpu.vsmpConsolidate="TRUE"
NUMA Awareness
Each processor chip on a NUMA host has local memory directly connected by one of more local memory controllers. Processes running on a CPU can access this local memory much faster than trying to access memory on a remote CPU in the same physical server.
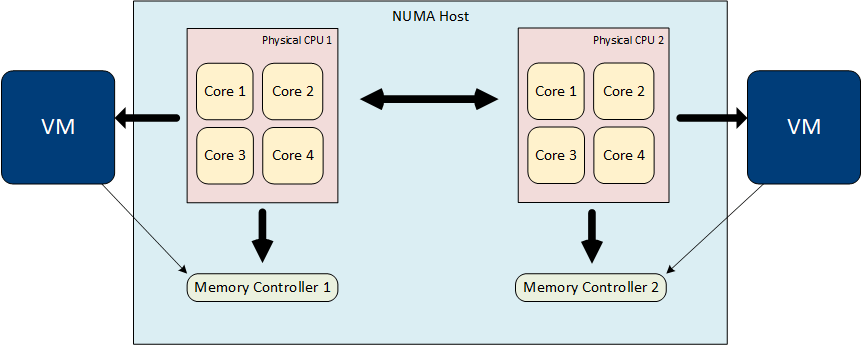
Poor NUMA locality can occur if a high percentage of a VMs memory is not local.
ESXi has NUMA awareness and using a NUMA scheduler, can restrict vCPUs to a single socket to use the cache. If required this can be overwritten using advanced configuration settings.
The CPU scheduler will try and keep a VMs vCPUs on the same NUMA home node to improve performance, however in some instances this might not be possible. For example:
A VM has more vCPUs that available per processor chip can support
In these situations NUMA optimisation is not used and can mean that the VMs memory is run on remote memory and not migrated to be local to the processor on which the vCPU is running.
A VMs memory size is greater than the memory available per NUMA node
In this situation you can get around this by splitting the number of sockets of the VM for example with a VM with 2 vCPUs if you configure it with 2 sockets with 1 core per socket it will then split the virtual sockets out and span two vNUMA boundaries.
You can work out roughly if the memory size exceeds the NUMA size by dividing the memory configured by the number of sockets. Although there are maximums supported on hosts so it’s worth double-checking in the server hardware configuration.
Note: Since vSphere 6.5, NUMA calculations don’t include memory size, it’s only concerned with compute dimensions and so you may find you workloads span multiple NUMA nodes. You can ensure that your workloads remain in the appropriate NUMA node by sizing your VMs core-to-socket ratio to reflect the pNUMA configuration of the CPUs.
Check with the hardware vendor to be sure about physical NUMA boundaries. The rough guide of memory divided by cores is typical but is not always the case. Once you have them you can calculate the best core/socket ratio.
The ESXi host is under moderate to high CPU loads
If a home node is overloaded the scheduler may move workloads to different, less utilized nodes which leads to poor NUMA locality. Typically this doesn’t lead to poor performance as NUMA will eventually migrate the VM back to it’s home node but frequent rebalancing can be a sign the host is CPU saturated.
vCPU Hot Add is enabled
Hot Add will disable vNUMA - https://kb.vmware.com/kb/2040375
If you have a NUMA sensitive workload like SQL, disable Hot Add as you want that VM to be aware of NUMA boundaries that only get shown when vNUMA is enabled.
vNUMA only comes into effect with VMs > 8 cores or those larger than the physical NUMA boundary. It was a feature added to ensure VMs were able to respect physical NUMA boundaries whilst still taking advantage of hypervisor features like DRS, vMotion.
Any VM smaller than 8 cores with Hot Add enabled will not disable vNUMA settings so if starting really small then scaling up you could leave this enabled until you get close to 8 cores. (Best bet is to right size it in the first place. :-) )
Any VM within the limits of the physical NUMA boundary won’t be affected by Hot Add.
Performance Monitoring with esxtop
esxtop provides a wealth of information and is very useful for investigating vCPU performance.
Key vCPU Metrics to Monitor
%USED - Per vCPU utilization
%WAIT - Per vCPU waiting for I/O - A sign of possible storage contention
%RDY - Per vCPU Ready Time - A sign of possible CPU contention. Aim for <10%
%CSTP - Per vCPU co-stop - A potential sign of too many vCPUs. Aim for <3%
%SWPWT - Per vCPU waiting for swap-in. A possible sign of RAM contention. Aim for <5%
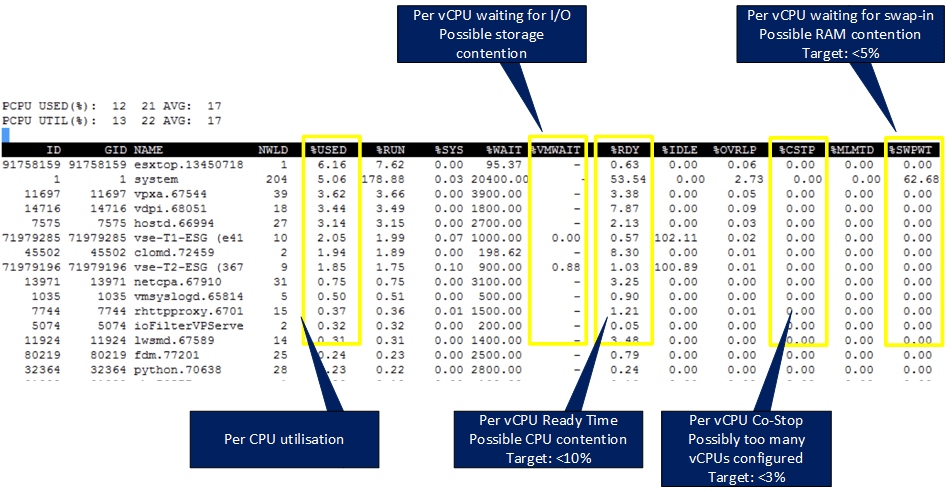
You can convert the %USED, %RDY and %WAIT values to real-time values by multiplying the value by the sample time.
e - Expanded view. Type in the GID to view expanded information
s - refresh delay in seconds, default 5 seconds
Important Monitoring Information
High usage values alone do not always indicate poor CPU performance, after all one of the main goals of virtualisation is to efficiently utilise available resources. It’s important to view it together with other metrics for example detecting high CPU utilisation isn’t an issue on it’s own, generally speaking, however high CPU and queuing may be a sign of a performance problem.
Analogy
To clarify this point let’s use an analogy.
Imaging you have a motorway with multiple lanes where the traffic is flowing freely. In this example you have high utilisation and good performance.

Now image you have the same motorway with lots of gridlocked traffic. A typical M25 during rush hour. Now we have high utilisation with queuing and a performance problem.

Ready Time
Ready time is the amount of time that the vCPU was ready to run but was asked to wait by the scheduler to wait due to an overcommitted physical CPU. It occurs when the CPU resources being requested by VMs exceed what can be scheduled by the physical CPUs.
Ready time remains the best indicator of potential CPU performance problems. Ready time reflects the idea of queuing in the CPU scheduler.
In esxtop, Ready Time is reported as %RDY. This value represents the time the CPU spent waiting during the last sample period as a percentage.
Key Ready Time Performance Indicators
Ready Time equal to or less than 5% is normal and has minimal effects on users.
Ready Time between 5-10% is worth investigating.
Ready Time greater than 10% usually means action is required to address the performance problems, even if there is no effect on users and systems continue to function normally.
High Ready Time (%RDY) and high utilisation (%USED) is usually a good sign of over commitment.
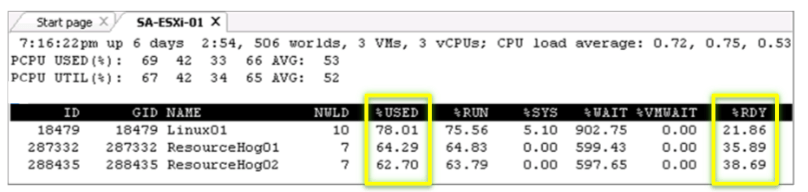
Addressing performance issues
A few examples of ways to resolve the performance issues.
- Reduce the number of VMs running on the host Increase the available CPU resources, for instance adding the host to a DRS cluster or adding additional hosts to the DRS cluster if the host is already in a cluster
- Performance tune the VMs to Increase the efficiency of CPU consumption within the Guest OS. Particularly relevant for VMs with high CPU demands
- Use resource controls such as shares and reservations to direct available resources to critical VMs if additional hosts are not available and CPU tuning is not possible
Guest CPU Saturation
When troubleshooting Guest CPU saturation it is important to have an understanding of the virtual machine CPU baseline performance. As a rough guide if the Guest CPU usage is high, greater than 75% (seen in top or Task Manager) with high peaks, 90% then you probably have a CPU saturation issue.
Host CPU Saturation Workflow
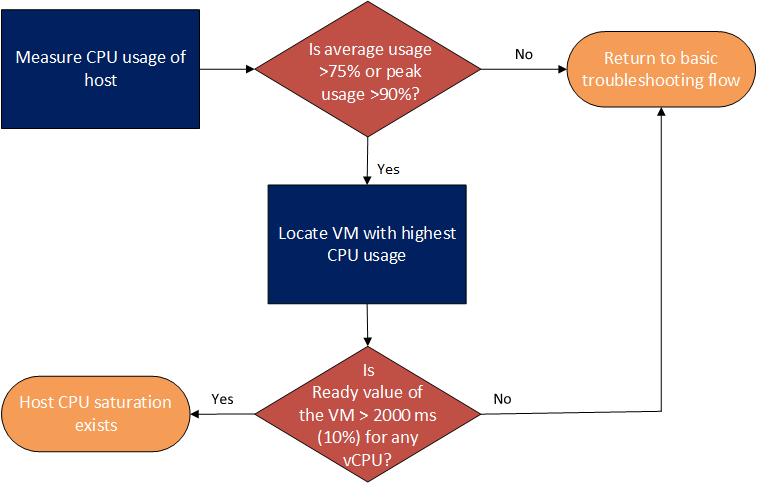
Resolutions
- Increase the CPU resources provided to the application
- Increase the efficiency with which the VM uses CPU resources by tuning the application and OS to address the causes of poor efficiency. This is particularly relevant if adding CPUs to the VM doesn’t address the underlying issues
Low Guest CPU Utilisation
| Cause | Resolution |
|---|---|
| High storage response times | Investigate slow or overloaded storage |
| High response times from external systems | Solution is application and/or environment dependent |
| Poor application or OS tuning | As above |
| Application pinned to cores in guest OS | Remove OS-level controls or reduce the number of vCPUs (See SMP VM Considerations below) |
| Too many configured vCPUs | Reduce the number of vCPUs |
| Restrictive resource allocations | Modify VM resource settings, in particular any limits in place |
SMP VM Considerations
With SMP VMs there could be performance problems related to the OS not utilising all the vCPUs assigned to it. This can happen in a few scenarios, such as when the:
- Guest OS is configured with a Uniprocessor kernel (HAL). Change the HAL to multi-processor
- Application is pinned to a single core in the Guest OS. If possible tune the OS to use all cores. If a single core is sufficient to meet the guest and application performance needs, reduce the number of vCPUs in the guest OS
- Application is single-threaded. Older applications are guilty of this, written to use a single thread. In these scenarios the Guest OS may try to spread the runtime of the single-threaded application across multiple processors. A working knowledge of the application is required to understand if this is likely to be the case, however as a rough guide if the application is running at maximum but the vCPU utilisation across any vCPUs is less than 100% then it is likely that the Guest OS is spreading the single-threaded application across multiple cores. The solution would be to reduce the number of vCPUs to a single vCPU in this situation. Note: Other situations could add to an artificial limit being placed on the SMP vCPUs such as poor application and Guest OS tuning or high I/O response times so ensure you evaluate the OS and application performance fully before reducing the number of vCPUs.
Tagged with: vSphere
Keep the conversation going on Twitter!
Reply with Twitter