VMware Virtual Machine Memory Guide
06 Feb 2013 by Simon Greaves
Memory Virtualisation Basics
When an operating system is installed directly onto the physical hardware in a non-virtualised environment, the operating system has direct access to the memory installed in the system and simple memory requests, or pages always have a 1:1 mapping to the physical RAM, meaning that if 4GB of RAM is installed, and the operating system supports that much memory then the full 4GB is available to the operating system as soon as it is requested. Most operating systems will support the full 4GB, especially if they are 64-bit operating systems. When an application within the operating system makes a memory page request, it requests the page from the operating system, which in turn passes a free page to the application, so it can perform its tasks. This is performed seamlessly.
The hypervisor adds an extra level of indirection. The hypervisor maps the guest physical memory addresses to the machine, or host physical memory addresses. This gives the hypervisor memory management abilities that are transparent to the guest operating system. It is these memory management techniques that allow for memory overcommitment.
To get a good understanding of memory behaviour within a virtualised environment, let’s focus on three key areas.
- Memory Terminology
- Memory Management
- Memory Reclamation
Memory Terminology
With an operating system running in a virtual machine the memory requested by the application is called the virtual memory, the memory installed in the virtual machine operating system is called the physical memory and the hypervisor adds an additional layer called the machine memory.
To help define the interoperability of memory between the physical RAM installed in the server and the individual applications within each virtual machine, the three key memory levels are also described as follows.
Host physical memory - Refers to the memory that is visible to the hypervisor as available on the system. (Machine memory)
Guest physical memory - Refers to the memory that is visible to the guest operating system running in the virtual machine. Guest physical memory is backed by host physical memory, which means the hypervisor provides a mapping from the guest to the host memory.
Guest virtual memory - Refers to a continuous virtual address space presented by the guest operating system to applications. It is the memory that is visible to the applications running inside the virtual machine.
To help understand how these layers inter-operate, look at the following diagram.
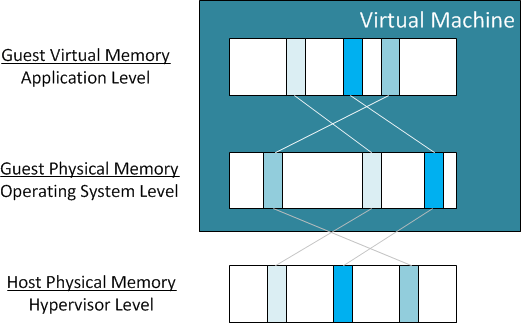
The Virtual memory creates a uniform memory address space for operating systems that maps application virtual memory addresses to physical memory addresses. This gives the operating system memory management abilities that are transparent to the application.
Memory Management
Hypervisor Memory Management
Memory pages within a virtualised environment have to negotiate an additional layer, the hypervisor. The hypervisor creates a contiguous addressable memory space for a virtual machine. This memory space has the same basic properties as the virtual address space that the guest operating system presents to the applications running on it. This allows the hypervisor to run multiple virtual machines simultaneously while protecting the memory of each virtual machine from being accessed by others.
The virtual machine monitor (VMM) controls each virtual machine’s memory allocation. The VMM does this using software-based memory virtualization.
The VMM for each virtual machine maintains a memory mapping from memory pages contained inside the the guest operating system. The mapping is from the guest physical pages to the host physical pages. The host physical memory pages are also called the machine pages.
This memory mapping technique is maintained through a Physical Memory Mapping Data (PMAP) structure.
Each virtual machine sees its memory as a contiguous addressable memory space. The underlying physical machine memory however may not be contiguous. This is because it may be running more than one virtual machine at any one time and it is sharing the memory out amongst the VMs.
The VMM sits between the guest physical memory and the Memory Management Unit (MMU) on the CPU so that the actual CPU cache on the processor is not updated directly by the virtual machine.
The hypervisor maintains the virtual-to-machine page mappings in a shadow page table. The shadow page table is responsible for maintaining consistency between the PMAP and the guest virtual to host physical machine mappings.
The shadow page table is also maintained by the virtual machine monitor. (VMM)
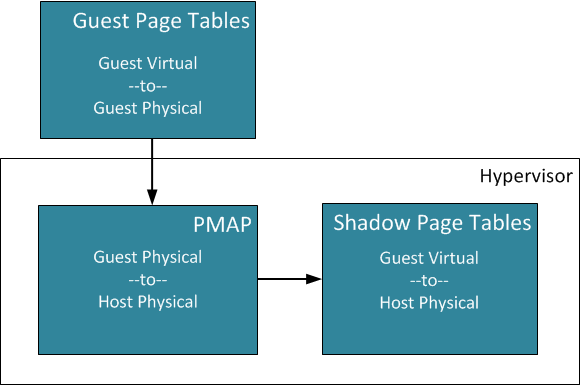
Each processor in the physical machine uses the Translation Lookaside Buffer (TLB) on the processor cache for the direct virtual-to-physical machine mapping updates. These updates comes from the shadow page tables.
Some CPU’s support hardware-assisted memory virtualisation. AMD SVM-V and Intel Xeon 5500 series CPU’s support it. These CPU’s have two paging tables, one for the virtual-to-physical translations and one for the physical-to-machine translations.
Hardware assisted memory virtualisation eliminates the overhead associated with software virtualisation, namely the overhead associated with keeping shadow page tables synchronised with guest page tables, as it uses two layers of page tables in hardware that are synchronized using the processor hardware.
One thing to note with hardware assisted memory virtualisation is that the TLB miss latency is significantly higher. As a result workloads with a small amount of page table activity will not have a detrimental effect using software virtualisation, whereas workloads with a lot of page table activity are likely to benefit from hardware assistance.
Application Memory Management
An application starts with no memory, it allocates memory through a syscall to the operating system. The application frees up memory voluntarily when not in use through an explicit memory allocation interface with the operating system.
Operating System Memory Management
As far as the operating system is concerned it owns all the physical memory allocated to it. That is because it has no memory allocation interface with the hardware, only with the virtual machine monitor. It does not explicitly allocate or free physical memory; it defines the in use and available memory by maintaining a free list and an allocated list of physical memory. The memory is either free or allocated depending on which list it resides on. This memory allocation list exists in memory.
Virtual Machine Memory Allocation
When a virtual machine starts up it has no physical memory allocated to it. As it starts up it ‘touches’ memory space, as it does this the hypervisor allocates it physical memory. With some operating systems this can actually mean the entire amount of memory allocated to the virtual machine is called into active memory as soon as the operating system starts, as is typically seen with Microsoft Windows operating systems.
Memory Reclamation
Transparent Page Sharing (TPS)
Transparent Page Sharing is on-the-fly de-duplication of memory pages by looking for identical copies of memory and deleting all but one copy, giving the impression that more memory is available to the virtual machine. This is performed when the host is idle.
Hosts that are configured with AMD-RVI or Intel-EPT hardware assist CPUs are able to take advantage of large memory pages where the host will back guest physical memory pages with host physical memory pages in 2MB pages rather than the standard 4KB pages where large pages are not used. This is because there will be less TLB misses and so will achieve better performance. There is a trade off though as large memory pages will not be shared as the chance of finding a 2MB memory pages that are identical are low and the overhead associated with doing the bit-by-bit comparison of the 2MB pages is greater than the 4KB page.
Large memory pages may still be broken down into smaller 4KB pages during times of contention as the host will generate 4KB hashes for the 2MB large memory pages so that when the host is swapping memory it can use these hashes to share the memory.
It is possible to configure advanced settings on the host to set the time to scan the virtual machines memory, Mem.ShareScanTime and the maximum number of scanned pages per second in the host, Mem.ShareScanGHz and the maximum number of per-virtual machine scanned pages using Mem.ShareRateMax.
Use resxtop and esxtop to view PSHARE field to monitor current transparent page sharing activity. This is available in memory view. See below.

You can disable TPS on a particular VM by configuring the advanced setting Sched.mem.Pshare.enable=false.
Ballooning
An ESXi host has no idea how much memory is allocated within a virtual machine, only what the virtual machine has requested. As more virtual machines are added to a host there are subsequently more memory requests and the amount of free memory may become low. This is where ballooning is used.
Provided VMware tools is installed, the ESXi host will load the balloon driver (vmmemctl) inside the guest operating system as a custom device driver.
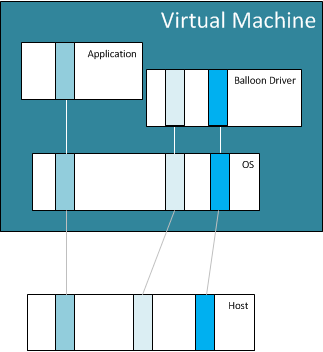
The balloon driver communicates directly with the hypervisor on the host and during times of contention creates memory pressure inside the virtual machine. This tells the virtual machine that memory is contended, and ‘inflates like a balloon’ by requesting memory from the guest and this memory is then ‘pinned’ by the hypervisor and mapped into host physical memory as free memory that is available for other guest operating systems to use. The memory that is pinned within the guest OS is configured so that the guest OS will not swap out the pinned pages to disk. If the guest OS with the pinned pages requests access to the pinned memory pages it will be allocated additional memory by the host as per a normal memory request. Only when the host ‘deflates’ the balloon driver will the guest physical memory pages become available to the guest again.
Ballooning is a good thing to have as it allows the guest operating systems to handle how much of it’s memory to free up rather than the hypervisor which doesn’t understand when a guest OS is finished accessing memory.
Take a look at the figure below and you can see how ballooning works. The VM has one memory page in use by an application and two idle pages that have been pinned by the hypervisor so that it can be claimed by another operating system.
Swapping
The memory transfer between guest physical memory and the host swap device is referred to as hypervisor swapping and is driven by the hypervisor.
The memory transfer between the guest physical memory and the guest swap device is referred to as guest-level paging and is driven by the guest operating system.
Host level swapping occurs when the host is under memory contention. It is transparent to the virtual machine.
The hypervisor will swap random pieces of memory without a concern as to what that piece of memory is doing at that time. It can potentially swap out currently active memory. When swapping, all segments belonging to a process are moved to the swap area. The process is chosen if it’s not expected to be run for a while. Before the process can run again it must be copied back into host physical memory.
Compression
Memory compression works by stepping in and acting as a last line of defence against host swapping by compressing the memory pages that would normally be swapped out to disk and compressing them onto the local cache on the host memory. This means that rather than sending memory pages out to the comparatively slow disk they are instead kept compressed on the local memory within the host which is significantly faster.
Only memory pages that are being sent for swapping and can be compressed by a factor of 50% or higher are compressed, otherwise they are written out to host-level swap file.
Because of this memory compression will only occur when the host is under contention and performing host-level swapping.
Memory compression is sized at 10% of the configured allocated memory on a virtual machine by default to prevent excessive memory pressure on the host as compression size needs to be accounted for on every VM.
You can configure a different value than 10% with the following advanced setting on the virtual machine. Mem.MemZipMaxPct.
When the compression cache is full the first memory compressed page will be decompressed and swapped out to the hypervisor level cache.
Tagged with: vSphere
Comments are closed for this post.